近端策略优化算法
近端策略优化算法(PPO)是一种进阶的强化学习算法,由 OpenAI 提出,并且在许多任务上都可以取得良好的效果。
其最核心的思想是限制 策略更新的幅度,从而使得 过去产生的经验可以运用到现在,极大地提高了采集到的样本 的 利用率,从而很好地提升了学习能力。
下面,我将根据一个具体的例子详细解释PPO算法的流程,以及其优越性。
首先,PPO 算法延续了 Actor-Critic 架构,我们拥有两个网络,分别是 策略网络 和 价值网络。
我们的优化目标是 使得
i)价值网络可以很好得估计动作的价值
ii)策略网络会赋予更优秀的动作以更大的可能性
我们首先初始化,两个网络的参数,随后,控制代理与环境进行互动,直到出现中止状态,或者达到足够的步骤,并将轨迹记录在 经验回放池(Experience Replay Buffer) 中。
接下来的问题是,我们的损失函数怎么设定?怎么达到我们优化的目标。
首先,根据轨迹,我们可以得到,实际的 Q(s, a)。例如在上面的情况下,
Q(s1, a1) = 1.3 +0.9\times0.7 +0.9\times0.9\times2.1
而根据我们的网络,我们可以获得网络对于 Q(s1, a1) 的预测值。
我们的目标是 使得 价值网络 可以很好地表达 实际 的价值。
这其实类似于监督学习,只不过 正确标签 不是 人类赋予 的,而是 代理 通过与环境交互得到的。
因此,可以直接利用均方损失函数,反向传播即可。
那么,如何更新策略网络呢?
这里涉及到 PPO 的核心思想——运用过去的经验,常规的强化学习方法会在更新策略网络后抛弃所有由原策略网络生成的轨迹,这使得样本的利用率极低。
如何才能利用这些过去的经验呢?
根据统计知识,
E_{x\sim p}[f(x)] = E_{x\sim q}[\frac{p(x)}{q(x)}f(x)],当 p,q 两种概率分布十分接近时。(重要性采样)
所以,尽管过去的轨迹,是在过去的网络上生成的,但是只要过去的网络和现在的网络差距不显著,我们仍然可以利用过去的轨迹,计算期望。
现在,不妨假设我们第二个图像的 Experience\space Replay\space Buffer 储存的是过去网络的轨迹,第三个图像的概率分布是现在网络的。
损失函数如下所示(常取 负数 作 梯度下降):
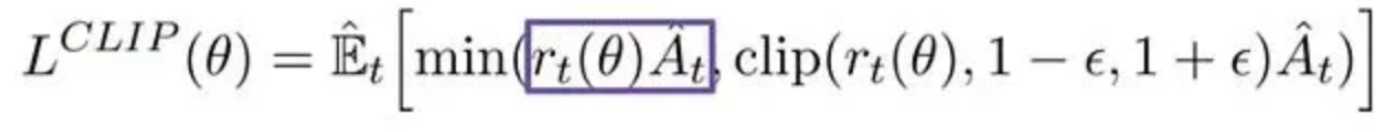
其中,r_t(\theta)=\frac{\pi_{\theta}(a|s)}{\pi_{\theta old}(a|s)} 。
首先考虑这样一个目标函数,L(\theta)=\mathbb{\hat{E}}_{t}[r_t(\theta)\hat{A}_t]
过去的分布 —— q
现在的分布 —— p