Deepseek论文精读
近来,DeepSeek 由于其较低的成本以及优秀的效果成了一个极度热门的话题。
我将制作一系列的视频分享 DeepSeek 公开的论文中提到的部分技术。如果你对此感兴趣,欢迎关注我的账号。
Multi-head Latent Attention(多头潜注意力)
多头潜注意力极大地提高了推理效率、支持更长的序列。
– Multi-head Attention(多头注意力)
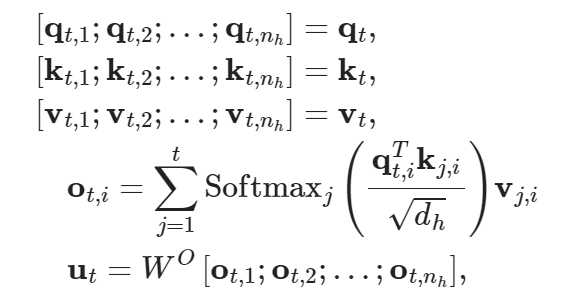
将向量切片后,进行注意力操作,对每个token,我们需要缓存 2n_{h}d_{h}l。
为什么需要对KV缓存,并且不需要对Q缓存呢?
这涉及到LLM在推理过程中的一个重要特点——自回归。
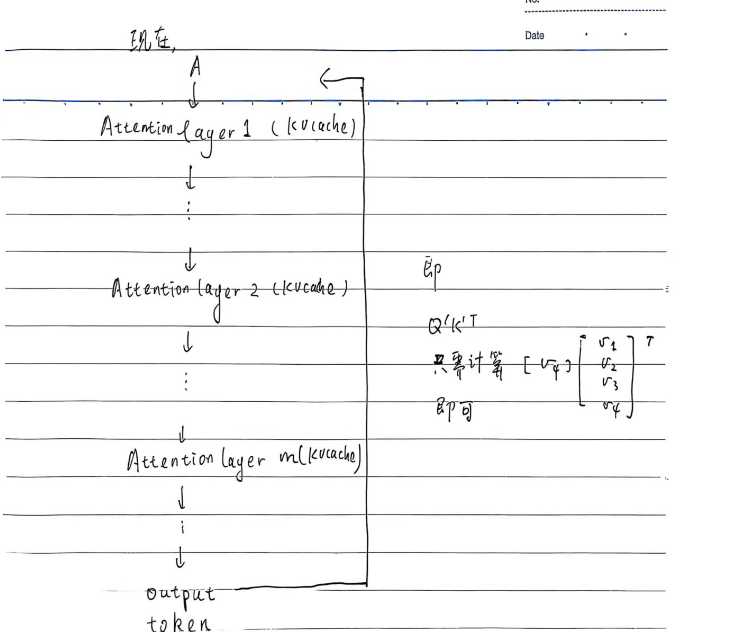
随着模型不断的输出,缓存就会越来越多——序列长度受限

– Multi-Query Attention
这是减少 KV 缓存的一个非常朴素的尝试。我们通过所有 head 共享同一个 KV 来减少缓存。实验证明,这样做性能会下降。
– Grouped-Query Attention
MQA 似乎一下子压缩的太多了。GQA 将 head 分组,同组内的 head 共享 KV,实现了一个相对平衡,而且通过调节分组的策略,我们还可以控制 缓存 和 性能 的权重。
– MLA
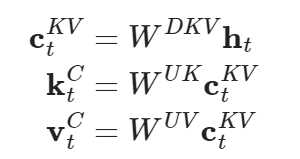
先对向量做低秩投影(将向量维数压缩,这与LoRA有些类似)
我们只需缓存 \textbf{c}_{t}^{KV} (存储量大大减小),左乘矩阵 W^{UK},W^{UV} 上投影,随后再进行常规的注意力操作即可。

兼容RoPE
MLA 还有一个问题——不兼容 RoPE。因为我们之前合并了两个矩阵(与位置无关),但位置矩阵与位置有关,这使得我们不再能直接记录合并后的矩阵。
MLA 最后是通过在 Q,K 后新增 d_r 个维度来进行 RoPE,提供位置信息。
而且不同的 head 共享新增的维度。这样我们额外缓存 d_r 个维度即可。
DeepseekMoE
deepseek 改进了 原有的 混合专家模型(MoE),下面让我们看一下 deepseek 是如何做的。
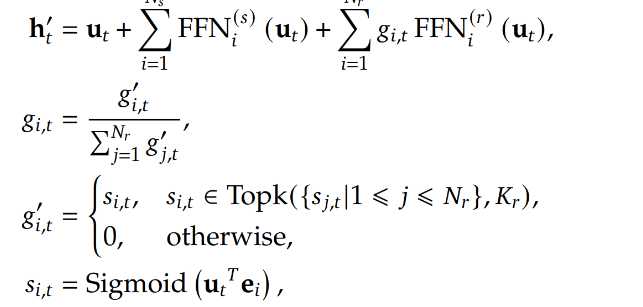
直接看公式的话比较抽象,让我们结合图来看。
输入经过 Router 后得到得分,选择最高的几个得分,只激活对应的 Experts,并且将得分归一化后,与对应 Experts 的输出相乘,再加上 输入向量、输入向量经公共 Experts 变换后的向量。
Auxiliary-Loss-Free Load Balancing
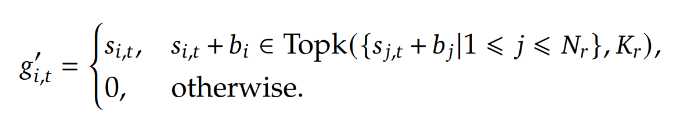
在选择最大的 K_r 个专家之前,为得分加入一个偏移,一旦某个专家过负载,我们将其所附加的偏移值减小,使得其更难被选择(同理,对于弱负载的专家,我们增加其偏移值),从而促进专家加载的平衡。
Complementary Sequence-Wise Auxiliary Loss
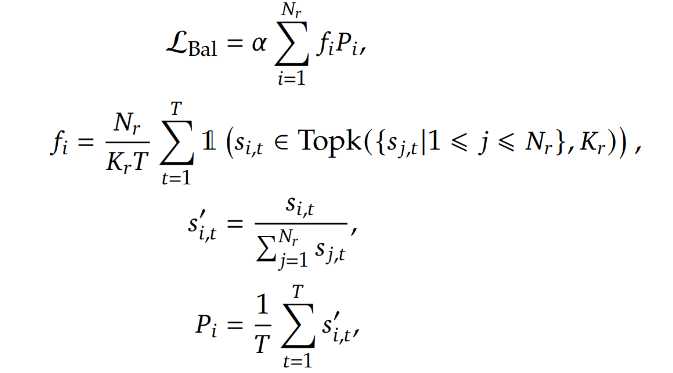
GRPO算法
GRPO 算法是在 PPO 算法的基础上进行改进的。
首先,我们需要明晰 PPO 或者 GRPO 这类强化学习算法是如何应用到大语言模型当中的。强化学习中的 状态 (环境)相当于 大语言模型 的 输入,动作 相当于 大语言模型 的 输出。
也就是说,大语言模型每预测一个 token, 都相当于 智能体 在 环境 中做了一次决策
PPO 算法有几点显著的不足:
PPO算法需要维护一个庞大的价值网络,这可能带来庞大的计算和储存开销,同时,PPO算法的价值网络将会尝试为每个动作打分,噪声可能更大
GRPO 主要的改进在于用多个输出的奖励信号均值作为基线,从而避免了使用 价值网络。
下面是 GRPO 的公式(这个公式有点问题):
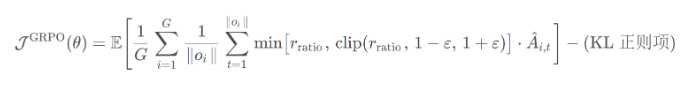
其中,KL 散度是通过一个小方差且无偏的估计器来计算的。
我们之前提到过,KL 散度 = D_{KL}(P||Q)=\sum_{x}P(x)log[\frac{P(x)}{Q(x)}],这样估计方差过大。
而在GRPO中,KL 散度通过 这个公式计算:
\sum_{x}P(x)[\frac{P(x)}{Q(x)} – log\frac{P(x)}{Q(x)} – 1]
首先,由于泰勒公式以及 log[\frac{P(x)}{Q(x)}]\approx0 ,省略高阶无穷小后可以证明:上面两个公式大致相等。
随后分析方差:不妨假设 \frac{P(x)}{Q(x)} 的均值为m
则 当 \frac{P(x)}{Q(x)}=m +\Delta 的时候,log[\frac{P(x)}{Q(x)}] 大致偏移 \frac{1}{m} * \Delta \approx \Delta
而 \frac{P(x)}{Q(x)} – log\frac{P(x)}{Q(x)} – 1 大致偏移 (1 – \frac{1}{m})*\Delta\approx 0,显然用后一种方式估计 KL 散度效果更好。